Melhorando a Performance de Consultas no Totvs Protheus – Parte 5

Fala pessoal,
Antes de lerem esse post, caso ainda não tenham lido os anteriores, sugiro que façam para seguirem a linha de raciocínio:
- https://www.fabriciolima.net/blog/2017/12/11/melhorando-a-performance-de-consultas-no-totvs-protheus-parte-1/
- https://www.fabriciolima.net/blog/2017/12/18/melhorando-a-performance-de-consultas-no-totvs-protheus-parte-2/
- https://www.fabriciolima.net/blog/2018/01/08/melhorando-a-performance-de-consultas-no-totvs-protheus-parte-3/
- https://www.fabriciolima.net/blog/2018/01/16/melhorando-a-performance-de-consultas-no-totvs-protheus-parte-4/
Hoje vamos analisar a query abaixo que estava demorando 28 segundos em um cliente e foi executada mais de 100 vezes em um dia:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECT B1_DESC , B1_COD , ISNULL(ZY_TIPO, '') TIPO FROM SB1010 LEFT JOIN SZY010 ON B1_COD = ZY_COD AND SZY010.D_E_L_E_T_ = '' AND ZY_DTDESAT = '' WHERE SB1010.D_E_L_E_T_ = '' AND B1_MSBLQL <> '1' AND B1_DESC LIKE '%NOMEPRODUTO%' AND B1_DESC LIKE '%%' AND B1_COD IN ( SELECT AIB_CODPRO FROM AIB010 WHERE D_E_L_E_T_ = '' AND AIB_DATVIG >= '20171215' AND AIB_CODFOR = '001234' AND AIB_CODTAB = '009' ); |
Plano:
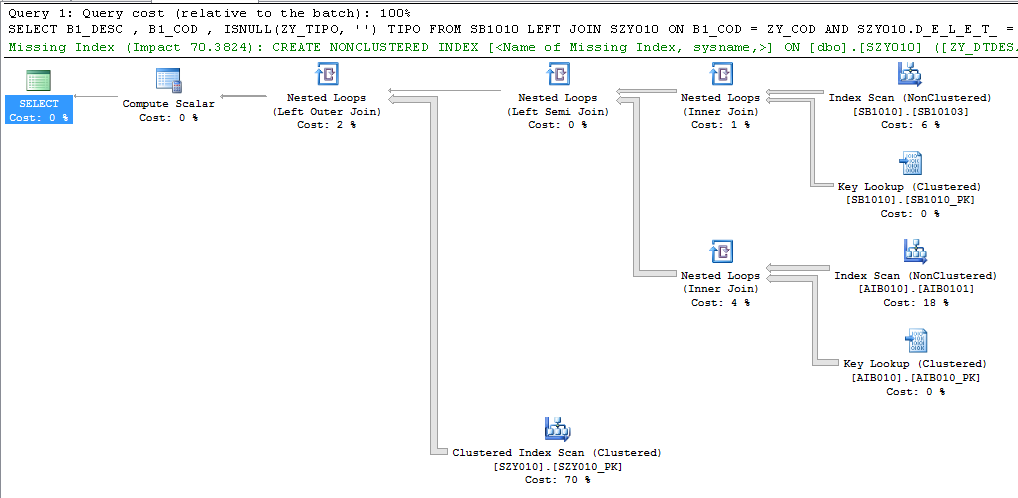
Mais uma vez o SQL nos sugere um índice:
|
1 2 3 4 |
CREATE NONCLUSTERED INDEX SZY010W01 ON [dbo].[SZY010] ([ZY_DTDESAT],[D_E_L_E_T_]) INCLUDE ([ZY_COD],[ZY_TIPO]) with(FILLFACTOR=90,DATA_COMPRESSION=PAGE) |
Digo e repito: Missing Index ajuda, mas nem sempre é a melhor solução.
Olha como essas duas colunas são usadas na query:
AND SZY010.D_E_L_E_T_ = ” AND ZY_DTDESAT = ”
Nada seletivo! Não seria uma boa coluna para um índice (exceto exceções).
Podemos ver facilmente que a query tem uma subquery. Se rodarmos essa subquery separada temos esse plano:
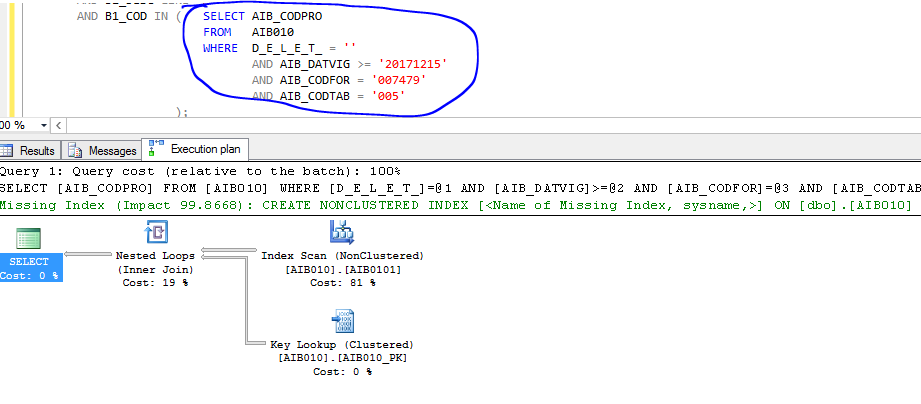
O SQL nos sugere outro índice que não seria o melhor a ser criado:
|
1 2 |
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[AIB010] ([AIB_CODTAB],[D_E_L_E_T_],[AIB_CODFOR],[AIB_DATVIG]) |
Ele sugere começar esse índice pela coluna AIB_CODTAB, mas será que ela é a mais seletiva dessa query?
Como sei qual é a coluna mais seletiva da query Fabricio?
Faça um count distinct nas colunas que quer validar:
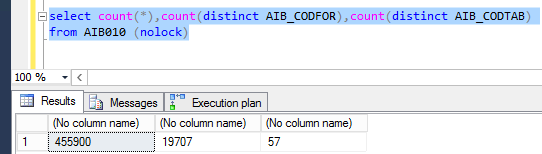
No nosso caso, a coluna AIB_CODFOR é muito melhor para ter um índice do que a coluna AIB_CODTAB, pois ela tem muito mais valores distintos. É uma coluna mais seletiva e um índice por ela deve beneficiar outras queries que acessam essa tabela.
Tudo isso até agora foi para mostrar que missed index ajuda, mas não é regra.
O que você faria para melhorar essa query então Fabrício?
Vou tentar induzir o SQL a rodar essa query da forma abaixo:
- Executar a subquery pois ela retorna só 200 linhas.
- Fazer a busca na tabela SB1 por ( B1_COD IN ), por ser uma coluna bem seletiva.
- Chegar até a tabela SZY010 pelo código com essa comparação (B1_COD = ZY_COD).
Como você consegue fazer isso Fabrício? Tem algum botão que você clica e escolhe os passos?
R: Ainda não tem botão. Ainda… Enquanto isso, conseguimos fazer criando índices manualmente!!!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE NONCLUSTERED INDEX AIB010W01 ON [dbo].[AIB010] ([AIB_CODFOR],[AIB_CODTAB],[AIB_DATVIG],[D_E_L_E_T_]) include(AIB_CODPRO) with(FILLFACTOR=90,DATA_COMPRESSION=PAGE) CREATE NONCLUSTERED INDEX SB1010W01 ON [dbo].[SB1010] (B1_COD,B1_DESC,B1_MSBLQL,D_E_L_E_T_) with(FILLFACTOR=90,DATA_COMPRESSION=PAGE) CREATE NONCLUSTERED INDEX SZY010W01 ON [dbo].[SZY010] ([ZY_COD],[ZY_DTDESAT],[D_E_L_E_T_]) INCLUDE([ZY_TIPO]) with(FILLFACTOR=90,DATA_COMPRESSION=PAGE) |
Após criar esses 3 índices que são bem pequenos, olhem como ficou o plano da query:
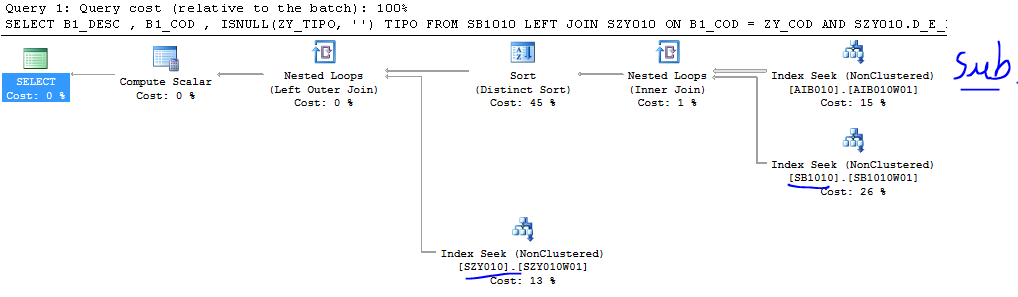
O SQL fez exatamente o que induzi ele a fazer. Pegou dados da subquery, buscou os códigos retornados por ela na SB1 e depois chegou na SZY pelo COD também.
E o tempo de 28 segundos Fabrício, foi para quanto?
WOW!!!!! Agora a query roda instantânea.
Consumo antes:
|
1 2 3 4 5 6 |
Table 'SZY010'. Scan count 1, logical reads 187725 Table 'AIB010'. Scan count 1, logical reads 2732873 Table 'SB1010'. Scan count 1, logical reads 4271 SQL Server Execution Times: CPU time = 28438 ms, elapsed time = 28673 ms. |
Consumo Depois:
|
1 2 3 4 5 6 |
Table 'SZY010'. Scan count 15, logical reads 30 Table 'SB1010'. Scan count 223, logical reads 673 Table 'AIB010'. Scan count 1, logical reads 5 SQL Server Execution Times: CPU time = 0 ms, elapsed time = 43 ms. |
Redução absurda com índices pequenos. Bem simples e eficiente….
Olhando no Trace de queries demoradas, a query ficou tão rápida que tenho que apelar e colocar um waitfor delay para poder visualizar e comparar:

Ela rodou em 0,1 segundos e a diferença de leituras de páginas (2.9 milhões para 802) e do consumo de CPU (27 mil para 62) é gigante!!!
Baita diferença.
É isso ai pessoal, melhoramos mais uma query no Protheus.
Até a próxima análise de query.
Atualizado no dia 07/10/2020:
Publiquei um curso com 11 horas de duração com toda minha experiência de anos no assunto e de dezenas de clientes Protheus atendidos:
Curso: Melhorando a Performance de Consultas no Totvs Protheus
Gravei uma aula grátis com 60 minutos de duração sobre o que você deve aprender para melhorar a performance no Protheus:
Gostou desse Post?
Curta, comente, compartilhe com os coleguinhas…
Assine meu canal no Youtube e curta minha Página no Facebook para receber Dicas de Leituras e Eventos sobre SQL Server.
Abraços,
Fabrício Lima
Microsoft Data Platform MVP
Consultor e Instrutor SQL Server
Trabalha com SQL Server desde 2006