Melhorando a Performance de Consultas no Totvs Protheus – Parte 4

Fala pessoal,
Antes de lerem esse post, caso ainda não tenham lido os anteriores, sugiro que façam para seguirem a linha de raciocínio:
- https://www.fabriciolima.net/blog/2017/12/11/melhorando-a-performance-de-consultas-no-totvs-protheus-parte-1/
- https://www.fabriciolima.net/blog/2017/12/18/melhorando-a-performance-de-consultas-no-totvs-protheus-parte-2/
- https://www.fabriciolima.net/blog/2018/01/08/melhorando-a-performance-de-consultas-no-totvs-protheus-parte-3/
Pegando mais uma query no Traces de queries demoradas. Essa query está demorando 18 segundos e fazendo um número absurdo de leituras na tabela SF2090.
Query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
SELECT A1_COD , A1_LOJA , A1_NOME , F2_DOC , F2_SERIE , CONVERT(DATE, F2_EMISSAO) AS F2_EMISSAO , ZZB_VOLUME , SA4.A4_COD , SA4.A4_NOME , SA1.A1_END , SA1.A1_COMPLEM , SA1.A1_BAIRRO , SA1.A1_EST , SA1.A1_MUN , SA1.A1_CEP , A1_CGC , SA1.A1_TEL , SA1.A1_DDD , A1_EMAIL , ZZB.ZZB_RASTRO , A4_YSERVIC , SF2.F2_VALBRUT , SF2.F2_VOLUME1 , VT1_API , VT1_ORDID , VT1_SEQUEN , F2_PBRUTO * 1000 F2_PBRUTO FROM SF2090 SF2 JOIN SA1040 SA1 ON A1_FILIAL = ' ' AND SA1.D_E_L_E_T_ = ' ' AND SA1.A1_COD = SF2.F2_CLIENTE AND SA1.A1_LOJA = SF2.F2_LOJA JOIN SA4090 SA4 ON A4_FILIAL = ' ' AND SA4.D_E_L_E_T_ = ' ' AND SA4.A4_COD = SF2.F2_TRANSP JOIN ZZB090 ZZB ON ZZB_FILIAL = '01' AND ZZB.D_E_L_E_T_ = ' ' AND ZZB.ZZB_DOC = SF2.F2_DOC AND ZZB.ZZB_SERIE = SF2.F2_SERIE JOIN SC5090 SC5 ON C5_FILIAL = '01' AND SC5.D_E_L_E_T_ = ' ' AND SF2.F2_DOC = SC5.C5_NOTA AND SF2.F2_SERIE = SC5.C5_SERIE LEFT JOIN VT1090 VT1 ON VT1_FILIAL = '01' AND VT1.D_E_L_E_T_ = ' ' AND SC5.C5_NUM = VT1.VT1_NUMPED OUTER APPLY ( SELECT TOP 1 * FROM VT4090 VT4 WHERE VT4_FILIAL = '01' AND VT4.D_E_L_E_T_ = ' ' AND VT4.VT4_ORDID = VT1.VT1_ORDID AND VT4_EMPFOR + VT4_FILFOR = '23234' ) VT4 WHERE SF2.F2_FILIAL = '01' AND SF2.D_E_L_E_T_ = ' ' AND SF2.F2_TIPO = 'N' AND SF2.F2_EMISSAO >= '20170315' AND SF2.F2_TRANSP IN ( '34534534', '34534534', '3453454' ) AND ZZB.ZZB_PLP = ' ' ORDER BY ZZB.ZZB_RASTRO DESC , F2_DOC; |
Leituras:
|
1 2 3 4 5 6 7 8 9 |
Table 'VT1090'. Scan count 0, logical reads 0 Table 'SA1040'. Scan count 0, logical reads 0 Table 'SF2090'. Scan count 1168821, logical reads 3725643 Table 'SC5090'. Scan count 1, logical reads 4316 Table 'ZZB090'. Scan count 1, logical reads 149 Table 'SA4090'. Scan count 1, logical reads 13 SQL Server Execution Times: CPU time = 15906 ms, elapsed time = 18008 ms. |
WOW!!! 3,7 milhões de leituras na tabela SF2.
Vamos ver o que está acontecendo no plano de execução:
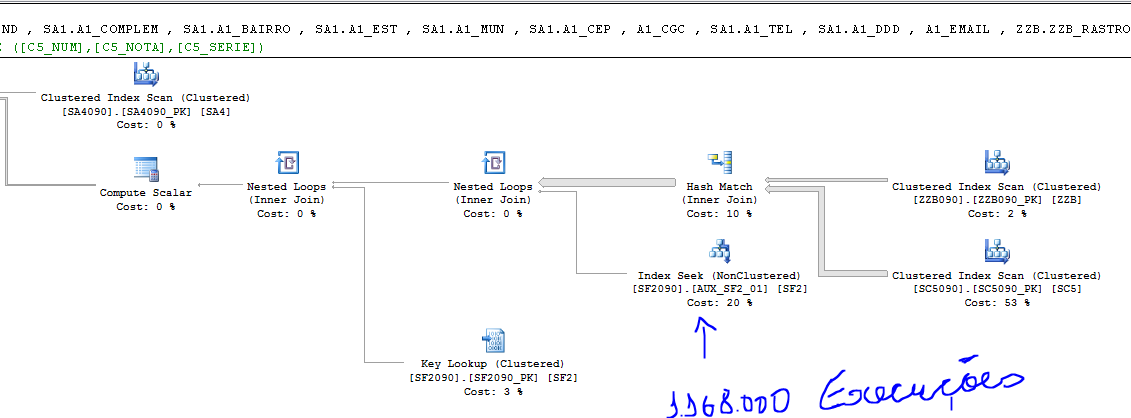
Como o plano é muito grande, peguei apenas a parte que envolve a tabela com mais leituras.
O SQL Server mais uma vez sugere um índice (Tabela SC5) que eu vou ignorar. Sempre falo que esses índices sugeridos ajudam, mas não dão sempre a melhor solução para uma query. Use com moderação!
O SQL Server junta os dados das tabelas ZZB090 e SC5090 e só depois faz um Seek na tabela SF2090. Só que ele faz isso mais de 1 milhão de vezes devido a quantidade grande de linhas que saiu do join das duas tabelas anteriores.
Mas por que ele faz isso Fabrício? Como podemos mudar isso?
Olhando apenas a cláusula where:
|
1 2 3 4 5 6 |
WHERE SF2.F2_FILIAL = '01' AND SF2.D_E_L_E_T_ = ' ' AND SF2.F2_TIPO = 'N' AND SF2.F2_EMISSAO >= '20170315' AND SF2.F2_TRANSP IN ( '34534534', '34534534', '3453454' ) AND ZZB.ZZB_PLP = ' ' |
Eu fiz um count com esse where e retornava apenas 6 mil linhas.
Se tivéssemos um covered index (com todas as colunas da tabela que foram usadas na query) e começando com F2_EMISSAO (mais seletiva desse WHERE), talvez o SQL escolheria começar a execução da query já pela tabela SF2.
A tabela SF2 tem apenas 76 mil linhas, então vai ser tranquilo criar esse índice com várias colunas:
|
1 2 3 4 |
CREATE NONCLUSTERED INDEX SF2090W01 ON [dbo].SF2090 (F2_EMISSAO, F2_TRANSP,F2_FILIAL,F2_TIPO, D_E_L_E_T_) INCLUDE (F2_DOC, F2_SERIE, F2_CLIENTE, F2_LOJA, F2_VEND1, F2_VALBRUT,F2_VOLUME1,F2_PBRUTO) with(FILLFACTOR=90,DATA_COMPRESSION=PAGE) |
Mais uma vez nessa série digo: WOWWWWWW!!!
A query de 18 segundos passou a rodar em 0 segundos com a criação de um índice em uma tabela de 76 mil linhas.
Segue o novo plano:
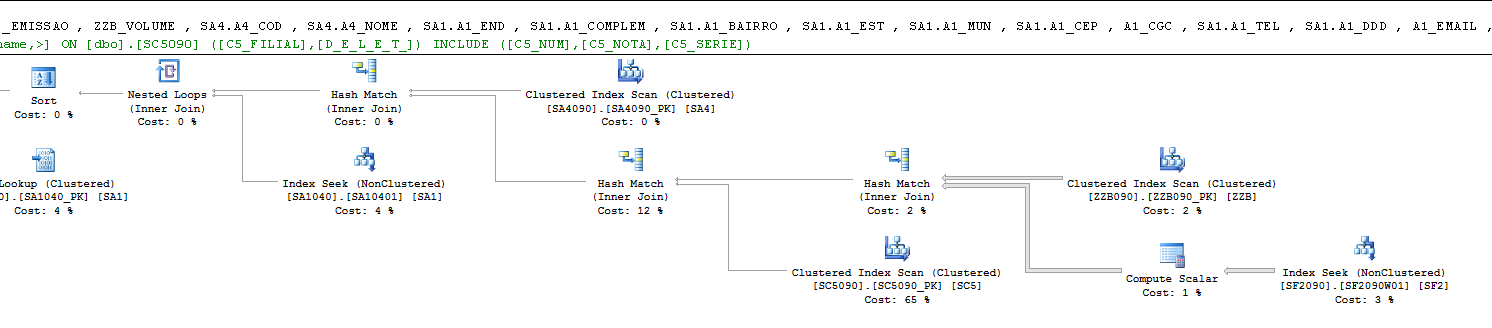
Ao invés de fazer um Seek 1 milhão de vezes na tabela SF2090, com o índice que eu criei, eu induzi o SQL Server a já fazer um Seek direto na SF2 e já fazer o join com a tabela ZZB.
O SQL continua nos sugerindo a criação de um índice, mas agora a query já roda em 0 segundos e a quantidade de leituras praticamente zerou, não vale criar mais um índice para essa query nesse momento.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
--Antes da criação do índice Table 'VT1090'. Scan count 0, logical reads 0 Table 'SA1040'. Scan count 0, logical reads 0 Table 'SF2090'. Scan count 1168821, logical reads 3725643 Table 'SC5090'. Scan count 1, logical reads 4316 Table 'ZZB090'. Scan count 1, logical reads 149 Table 'SA4090'. Scan count 1, logical reads 13 SQL Server Execution Times: CPU time = 15906 ms, elapsed time = 18008 ms. --Após a criação do índice Table 'VT1090'. Scan count 0, logical reads 0 Table 'SA1040'. Scan count 0, logical reads 0 Table 'SF2090'. Scan count 1, logical reads 156 Table 'ZZB090'. Scan count 1, logical reads 149 Table 'SA4090'. Scan count 1, logical reads 13 SQL Server Execution Times: CPU time = 47 ms, elapsed time = 124 ms. |
Redução absurda com um índice pequeno. Bem simples e eficiente….
Olhando no Trace de queries demoradas, a query ficou tão rápida que tenho que apelar e colocar um waitfor delay para poder visualizar e comparar:

Ela rodou em 0,26 segundos e a diferença de leituras de páginas (3.8 milhões para 1.518) e do consumo de CPU (16 mil para 250) é gigante!!!
Baita diferença.
É isso ai pessoal, melhoramos mais uma query no Protheus.
Até a próxima análise de query.
Atualizado no dia 07/10/2020:
Publiquei um curso com 11 horas de duração com toda minha experiência de anos no assunto e de dezenas de clientes Protheus atendidos:
Curso: Melhorando a Performance de Consultas no Totvs Protheus
Gravei uma aula grátis com 60 minutos de duração sobre o que você deve aprender para melhorar a performance no Protheus:
Gostou desse Post?
Curta, comente, compartilhe com os coleguinhas…
Assine meu canal no Youtube e curta minha Página no Facebook para receber Dicas de Leituras e Eventos sobre SQL Server.
Abraços,
Fabrício Lima
Microsoft Data Platform MVP
Consultor e Instrutor SQL Server
Trabalha com SQL Server desde 2006
Show em Fabrício, parabéns pelo trabalho e obrigado por compartilhar com tantos detalhes.
Abraço.
Valeu Romano!!!
Abraço
Fabrício, Pode me ajudar.
Não sou muito bom em querys, e preciso saber o seguinte:
Ver no campo E2_ORIGEM, quando conter ‘MATA100’ ou ‘MATA103’, pegar o numero do titulo E2_NUM, e a partir desse numero buscar na nota de entrada(item_ SD1->D1_DOC o mesmo numero para na realidade achar qual foi o pedido de compras que gerou essa nf e titulo no contas a pagar.
Mas não para, depois disso ele quer ver todos campos da SC7 relacionado a pesquisa acima.
Pode me ajudar?
Olá Silas,
Você teria que validar os filtros que estão sendo utilizados na query, as colunas envolvidas no WHERE e JOIN, verificar se poderia criar algum índice ou se ela pode ser reescrita para melhorar o desempenho.
Utilize o Plano de Execução para entender melhor o que a query está fazendo. No mais, só analisando a mesma com mais calma para entender melhor a sua situação.
Espero ter ajudado.
Abraço.
Fabricio