Melhorando a Performance de Consultas no Totvs Protheus – Parte 1
Fala Pessoal,
No meu dia a dia de Consultor SQL Server, atendo muitos clientes com Totvs Protheus e SQL Server. Inclusive já compartilhei algumas experiências com vocês aqui no Blog:
- 5 motivos para quem utiliza o Protheus (Totvs) contratar um DBA SQL Server
- Migrando um SQL Server 2008 Totvs Protheus para o SQL Server 2016 Standard
Como já disse nesses posts, os índices padrões do Protheus não são os melhores para todas as consultas que são realizadas pelo ERP. Se ninguém nunca criou índices customizados no seu ambiente, certamente você tem margem para melhoria de performance no sistema da Totvs.
Nesse cenário, passo bastante tempo melhorando a performance de ambientes Protheus com a criação de índices.
E como eu faço isso Fabrício?
O primeiro passo é você identificar as queries mais demoradas, que normalmente são as queries que os usuários reclamam, pois ficam muito tempo esperando uma resposta das telas.
Criando meus Alertas ou o meu CheckList, automaticamente você já implementa uma rotina para monitorar as queries que demoram mais de X segundos no seu BD:
- Vídeo: Criando 15 Alertas no SQL Server em apenas 5 minutos
- Criando um E-mail de CheckList Diário no SQL Server
Feito isso, agora é analisar uma a uma as queries que mais consomem CPU, que fazem mais Leituras ou as queries que mais se repetem em nosso log.
Para tentar ajudar vocês nessa atividade de análise de queries, vou realizar uma série de posts curtos com a análise de 1 query por post para verem como a criação de índices customizados se faz necessária no Protheus.
Vamos começar por uma query bem simples, mas que é um caso REAL de produção.
Em um dos meus clientes, peguei a seguinte query sendo executada algumas vezes durante o dia:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT R_E_C_N_O_ FROM dbo.CT2010 WHERE D_E_L_E_T_ = ' ' AND ( CT2_CREDIT = '65454565464' ) ORDER BY CT2_FILIAL DESC , CT2_DATA DESC , CT2_LOTE DESC , CT2_SBLOTE DESC , CT2_DOC DESC , CT2_LINHA DESC , CT2_TPSALD DESC , CT2_EMPORI DESC , CT2_FILORI DESC , CT2_MOEDLC DESC , R_E_C_N_O_ DESC; |
Sempre falo isso nas minhas palestras e treinamentos. A primeira coisa que você deve fazer ao começar a analisar uma query é
|
1 2 |
set statistics io,time on -- para ver a quantidade de leitura e consumo de CPU da query --ctrl+M para ver o plano real da query após a execução |
Ao setar essas opções e executar a query, podemos ver o plano de execução abaixo:

A query demorou 5.7 segundos e teve o seguinte consumo:
|
1 2 3 4 5 |
Table 'CT2010'. Scan count 3, logical reads 91143 SQL Server Execution Times: CPU time = 10531 ms, elapsed time = 5764 ms |
O SQL está fazendo um Scan em um índice nonclustered, mas como ele não tem todas as colunas que precisa nesse índice, depois ainda faz um Key Lookup no índice clustered para pegar o resto das colunas que faltam.
Todos os índices dessa tabela começam com a coluna CT2_FILIAL, que não é uma coluna com dados muito seletivos para descer rápido na árvore do índice e dar o resultado da query.
No caso dessa query, o próprio SQL Server está te sugerindo um índice.
Pô Fabrício… aí ficou fácil…. nem precisava de um post…
Mas mesmo que ele não te sugerisse, quando você vê uma cláusula como essa em um WHERE, o SQL Server está praticamente te implorando para você criar um índice por essa coluna (exceto quando essa coluna não é muito seletiva).
|
1 |
AND ( CT2_CREDIT = '65454565464' ) |
Palavras do SQL Server para você que está analisando a query:
- “Meu amigo, por favor, crie um índice nessa coluna CT2_CREDIT”
- “Estou trabalhando demais, economiza meu processamento aí. Please!!!”
- “Me ajuda que eu te ajudo DBA!”
- “Dev, entende como esse negócio de índice funciona e cria um aí para mim… help!! “
Nossa Resposta: OK SQL. Deixa comigo SQL. #tamojunto
Quando o SQL te sugere um índice você faz o que? Cria né! Lógico! Mel na chupeta! Muito fácil! Easy!
Só tem um porém. Essa tabela tem 48 milhões de registros.
Olha o tamanho do índice que o SQL sugeriu criar:
|
1 2 3 |
CREATE NONCLUSTERED INDEX CT2010W01 ON [dbo].[CT2010] ([CT2_CREDIT],[D_E_L_E_T_]) INCLUDE ([CT2_FILIAL],[CT2_DATA],[CT2_LOTE],[CT2_SBLOTE],[CT2_DOC],[CT2_LINHA],[CT2_MOEDLC],[CT2_EMPORI],[CT2_FILORI],[CT2_TPSALD]) |
Vai demorar bastante para criar e ficar bem grande. Se fosse tão fácil assim o cliente nem nos contratava.
E se eu tentar criar um índice só pela coluna CT2_CREDIT? Será que já é suficiente para resolver meu problema e fazer a query rodar rápida e sem consumir muitos recursos?
Se a quantidade de registros retornada pela query for baixa, fazer um lookup não é tão custoso assim. Vamos tentar:
|
1 2 3 |
CREATE NONCLUSTERED INDEX CT2010W01 ON [dbo].[CT2010] ([CT2_CREDIT]) with(FILLFACTOR=90,DATA_COMPRESSION=PAGE) |
A criação desse índice levou 5 minutos (discos SSD) e o índice ficou com o 420 MB de tamanho. Imagina o índice sugerido com muitas colunas.
WOW!!!! Ao rodar a query novamente ela passou a rodar de forma instantânea:
|
1 2 3 4 |
Table 'CT2010'. Scan count 1, logical reads 4 SQL Server Execution Times: CPU time = 0 ms, elapsed time = 44 ms. |
Esse é o novo plano da query:
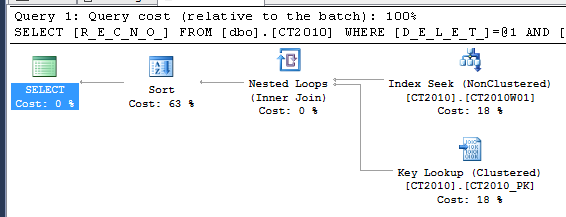
Aquele índice gigante que o SQL sugeriu, iria fazer apenas um seek. O meu índice que é bem menor, fez o seek + lookup. Contudo, podemos ver que já resolveu totalmente o problema da query.
Dessa maneira, decidi manter esse índice menor para ter menos impacto na manutenção dele.
Após criarmos um índice, conseguimos acompanhar se ele está sendo bem utilizado ou não com a query abaixo:
|
1 2 3 4 5 6 7 |
select getdate(), o.Name,i.name, s.user_seeks,s.user_scans,s.user_lookups, s.user_Updates, isnull(s.last_user_seek,isnull(s.last_user_scan,s.last_User_Lookup)) Ultimo_acesso,fill_factor from sys.dm_db_index_usage_stats s join sys.indexes i on i.object_id = s.object_id and i.index_id = s.index_id join sys.sysobjects o on i.object_id = o.id where s.database_id = db_id() and o.name in ('CT2010') order by s.user_seeks + s.user_scans + s.user_lookups desc |
Bem legal para ver se nosso índice está sendo MUITO utilizado ou pouco. Se por acaso um índice customizado parar de ser utilizado, sua função é excluir esse índice para que ele não gere mais I/O sem necessidade (monitoramento contínuo).
Olhando no Trace de queries demoradas, a query ficou tão rápida que nem aparece mais lá. Tenho que apelar e colocar um waitfor delay para poder visualizar e comparar:
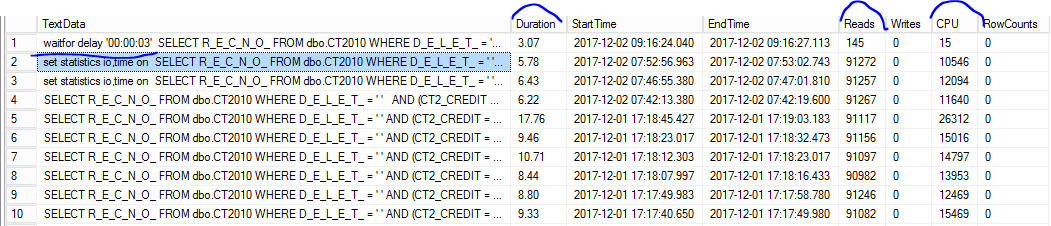
Ela rodou em 0,07 segundos e a diferença de leituras de páginas (91 mil para 145) e do consumo de CPU (10 mil para 15) é considerável conforme pode ser visto acima.
É isso ai pessoal, essa é a parte 1 dessa série de posts onde faremos a análise de queries em um ambiente real do Protheus.
Atualizado no dia 07/10/2020:
Publiquei um curso com 11 horas de duração com toda minha experiência de anos no assunto e de dezenas de clientes Protheus atendidos:
Curso: Melhorando a Performance de Consultas no Totvs Protheus
Gravei uma aula grátis com 60 minutos de duração sobre o que você deve aprender para melhorar a performance no Protheus:
Gostou desse Post?
Curta, comente, compartilhe com os coleguinhas…
Assine meu canal no Youtube e curta minha Página no Facebook para receber Dicas de Leituras e Eventos sobre SQL Server.
Até a próxima.
Abraços,
Fabrício Lima
Microsoft Data Platform MVP
Consultor e Instrutor SQL Server
Trabalha com SQL Server desde 2006
Opa Fabricio. Bom dia.
Estava no SQL Saturday de BH, o louco que parou voce no aeroporto e chegou ‘atrasado’ na palestra. Kkkkk.
Enfim. Tive uma dúvida com esse post.
Pelo custo de manutençao e o peso do indice, voce optou criar um indice que faria um seek mais lookup que tambem retornaria rapidamente sua consulta, o que entao te atenderia, blz.
Porém, nesse caso pela quantidade de linhas retornadas fez o SQL optar por fazer o lookup. Nao seria arriscado a tabela crescer e passar fazer um scan? Tornando a consulta lenta novamente e sendo necessario sua intervençao para aplicar a soluçao anterior? ( Indice pesado que voce optou nao criar ).
Opa… Imagina se tivermos que criar um indice gigante para cada query… uma hora vamos atrapalhar mais do que ajudar…
Logo… evite o quanto puder… se a query ficar lenta depois, você vai pegar ela no seu monitoramento e vai decidir o que fazer com ela… depois…
Entendido.
Obrigado.
Bom dia Fabrício. Primeiramente, parabéns pelos seus artigos, ótimo trabalho. Gostaria de uma informação, trabalho com Sql Server 2012 Enterprise e Totvs Protheus V12.1.17 e estou pensando em particionar minhas tabelas devido ao alto volume de dados, hoje 1.4 TB, você já trabalhou com tabelas particionadas no Totvs Protheus? Ele se comportou bem?
Boa Noite Cristian,
Seria divertido mas nunca cheguei a fazer um particionamento no protheus.
Vai ter ganho de performance se colocar em discos diferentes.
Bom dia Fabrício. Primeiramente parabéns pelo seus postes, ótimo trabalho.
Trabalho hoje com SQL Server 2012 e Protheus V 12.1.17, estou pensando em particionar minhas tabelas devido ao tamanho do Banco de Dados, 1.4 TB, você já trabalho com particionamento de tabelas e Protheus? Como ele se comportou?
Desde já agradeço
Bom dia Fabrício.
Hoje possuo um Storage com 2 array com 10 disco (sendo 8 de 10k e 2 SSD) em Raid 5, a performa-se já é legal, porem com o crescimento do banco seria necessário aquisição de mais discos, estava pensando em particionar por ano, montar um array de discos 7k para armazenamento (já que essa composição com discos de alta performa-se não é barata) e colocar os anos que não possuem acessos frequentes nesse array com menor velocidade, mantendo no ambiente de alta performa-se o file Group PRIMARY, onde manterei as tabelas de cadastros, e o ano em vigência que é onde tenho alto volume de escrita e leitura. Com sua experiencia, acha que terei algum problema com esse senário?
Grande Abraço.
Fabricio, bom dia primeiramente parabéns pela série de posts para otimização de consultas do Protheus.
Comecei a pouco tempo com esse sistema e algumas pessoas comentaram algumas coisas que vi que não utilizou para criar os índices…. Então acho que são mitos.. kk
Existe alguma regra para que seja criado os índices??? (nome padrão, ser aplicado em mais de uma tabela, acrescentar no dicionário de dados etc).
Desde já muito obrigado
Grande abraço.
Sds,
Jeferson
Bom Dia, Sobre padronização seria bom abrir um chamado na totvs para confirmar, mas já nos pediram para manter um padrão com nome da tabela + W + 01..02..03 no indices
Sobre criar no dicionario, alguns clientes adicionam outros não.
Só aplico em tabelas que tem queries lentas… não em todas as tabelas da mesma empresa…