Improve the performance of a query that uses ” like ‘%String%’ ” changing only the collation
Hi Folks,
In this blog post, I will give you a very useful tip to improve the performance of a query that uses ” like ‘%String%’ “.
How often do you have to use a query like this?
|
1 2 3 |
Select Columns,... from Table where Name like '%String%' |
Reading the great book SQL Server 2012 Internals, on page 230, we have:
“Another case where the collation can make a huge difference is when SQL Server has to look at almost all characters in the strings. For instance, look at the following:
SELECT COUNT(*) FROM tbl WHERE longcol like ‘%abc%’
This might execute 10 time faster or more with a binary collation than a nonbinary Windows colation. Also, with varchar data, this executes up to seven or eight times faster with a SQL collation than with a Windows collation. If you have a varchar column, you can speed this up by forcing the collation as follows:
SELECT COUNT(*) from tbl
WHERE longcol COLLATE SQL_Latin1_Genneral_CP_CI_AS LIKE ‘%abc%’ “
That’s a very important information. Let’s do some tests and see what’s happen.
I will create a table with a varchar column and populate it with a lot of data.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE table dbo.Test_Collation_SQL ( Id_Table int identity(1,1) PRIMARY KEY, Dt_Log datetime, Ds_Name varchar(50) ) -- Generate a lot of data. Can take a while... INSERT INTO dbo.Test_Collation_SQL select getdate(), REPLICATE('A',50) GO 10 INSERT INTO dbo.Test_Collation_SQL(Dt_Log,Ds_Name) SELECT Dt_Log,Ds_Name FROM Test_Collation_SQL GO 22 |
Now, I will insert two rows with my name to search later:
|
1 2 3 4 5 |
insert into dbo.Teste_Collation_SQL select getdate(), 'Fabricio Lima 1' insert into dbo.Teste_Collation_SQL select getdate(), '- Fabricio Lima 2' |
Then I will create a index to try do help my query, just like everyone do:
|
1 |
CREATE NONCLUSTERED INDEX SK01_Test_Collation_SQL ON Test_Collation_SQL(Ds_Name) WITH(FILLFACTOR=90) |
The size of the table is:
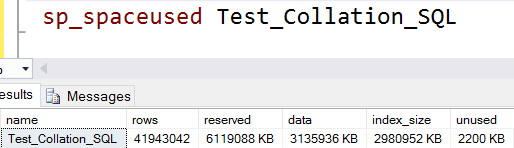
Now I will enable this option to compare the results
|
1 2 |
SET STATISTICS IO ON SET STATISTICS TIME ON |
I also enable the Actual Execution Plan to see what’s SQL doing: CTRL+M
My instance has this Windows Collation: Latin1_General_CI_AI
My Database and Column also has the same Collation: Latin1_General_CI_AI
Test 1: Using my default Windows Collation: Latin1_General_CI_AI
|
1 2 3 |
SELECT COUNT(*) FROM Test_Collation_SQL WHERE Ds_Name LIKE '%Fabricio%' |
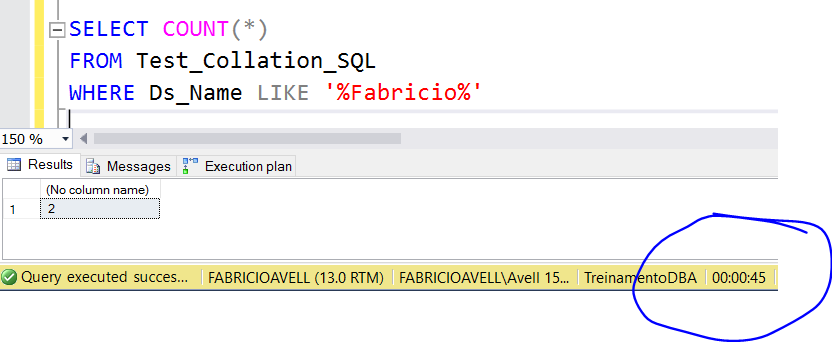
Reads
Table ‘Test_Collation_SQL’. Scan count 9, logical reads 373572
CPU Time
SQL Server Execution Times:
CPU time = 348922 ms, elapsed time = 45679 ms.
Teste 2: Forcing a SQL Server collation and searching the same thing
|
1 2 3 |
SELECT COUNT(*) FROM TreinamentoDBA..Teste_Collation_SQL WHERE Descrição COLLATE SQL_Latin1_General_CP1_CI_AI LIKE '%Fabricio%' |
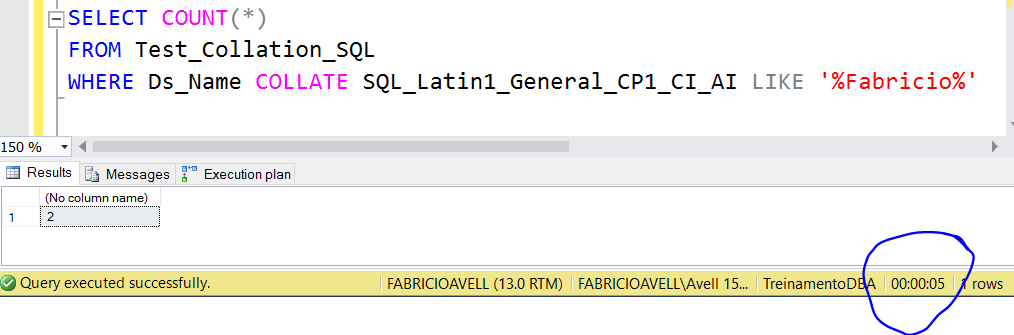
Reads
Table ‘Test_Collation_SQL’. Scan count 9, logical reads 374622
CPU Time
SQL Server Execution Times:
CPU time = 37265 ms, elapsed time = 5300 ms.
The logical reads is almost the same, but we have a huge difference in the CPU Time.
The two queries have the same execution Plan doing a Scan on the index SK01_Test_Collation_SQL and working on parallel.
Results
Windows Collation: 45 seconds and 348922 ms of CPU time
SQL Collation: 5 seconds and 37265 ms of CPU time
Unbelievable!!!
Why does it happen?
This article help us to understand:
https://support.microsoft.com/en-us/help/322112/comparing-sql-collations-to-windows-collations
“If you are storing and handling your data by using non-Unicode data types (char, varchar, text), and you are using a SQL collation, string comparisons will be performed with a non-Unicode SQL sort order.
If you are storing and handling your data by using non-Unicode data types (char, varchar, text), and you are using a Windows collation, string comparisons will be performed with the Unicode sorting rules. This may cause certain operations that are unusually dependent on string sorting performance to take longer and to use more CPU than a similar operation that is performed with a SQL collation.”
I did another test with more data and the results are:
Windows Collation: 1 minute and 48 seconds
SQL Collation: 12 seconds
It’s like a magic! A huge difference!!
Enjoy and share with your friends…
Thanks to my friend Edvaldo (Blog) for the revision of the text.
Fabrício França Lima
MCITP – Database Administrator
The article in English is a great job! But when I saw the call I thought I’d see an equal video had in Portuguese! rsrsrs Congratulations!
Next steps videos in english. \o/
kkkkk
It will take some time….
Great post. I had a query from a client and nothing that I did boost the performance.
But this little, and great tip. solved the issue. Thx a lot.
cool!!
Thank You.