
Melhorando a Performance de Consultas no Totvs Protheus – Parte 7

Fala pessoal,
Como tudo que é bom dura, pouco, esse é o último episódio da nossa série de artigos de Tuning de consultas no Totvs Protheus.
Lembrando que essas dicas valem para queries de outros sistemas também.
Antes de lerem esse post, caso ainda não tenham lido os anteriores, sugiro que façam para seguirem a linha de raciocínio:
- https://www.fabriciolima.net/blog/2017/12/11/melhorando-a-performance-de-consultas-no-totvs-protheus-parte-1/
- https://www.fabriciolima.net/blog/2017/12/18/melhorando-a-performance-de-consultas-no-totvs-protheus-parte-2/
- https://www.fabriciolima.net/blog/2018/01/08/melhorando-a-performance-de-consultas-no-totvs-protheus-parte-3/
- https://www.fabriciolima.net/blog/2018/01/16/melhorando-a-performance-de-consultas-no-totvs-protheus-parte-4/
- https://www.fabriciolima.net/blog/2018/01/23/melhorando-a-performance-de-consultas-no-totvs-protheus-parte-5/
- https://www.fabriciolima.net/blog/2018/01/30/melhorando-a-performance-de-consultas-no-totvs-protheus-parte-6/
Analisando mais umas das queries que demoram mais de 3 segundos em um cliente:
SELECT Z6_RETORNO AS 'DIRETOR',
ZV_DESCRIC AS 'REGIONAL',
ZM_EMP,
RE0_FILIAL AS 'FILIAL',
CASE
WHEN RE0_RECLAM = 'VARIOS' THEN
'VARIOS'
ELSE
RD0_NOME
END AS 'NOME',
RE5_DESCR AS 'TPDESP',
RC1_NUMTIT,
RC1_VALOR,
RC1_VENCTO,
A2_NOME,
A2_CGC,
A2_BANCO,
A2_AGENCIA,
A2_NUMCON,
RTRIM(ED_CODIGO) + ' - ' + ED_DESCRIC AS NATUREZA
FROM RC1480 AS RC1
INNER JOIN RE5010 AS RE5
ON RE5_TABELA = 'RC1'
AND RC1_TPDESP = RE5_CODIGO
AND RE5.D_E_L_E_T_ = ' '
INNER JOIN RE0480 AS RE0
ON RE0_FILIAL = RC1_FILTIT
AND RE0_NUM = RC1_PRONUM
AND RE0.D_E_L_E_T_ = ' '
INNER JOIN RD0010 AS RD0
ON RD0_CODIGO = RE0_RECLAM
AND RD0.D_E_L_E_T_ = ' '
INNER JOIN SZ6010 AS SZ6
ON Z6_TABELA = 'DIR_REGIO'
AND Z6_ITEM = RE0_XCDDIR
AND SZ6.D_E_L_E_T_ = ' '
INNER JOIN SZV010 AS SZV
ON ZV_REGIONA = RE0_XREGIO
AND SZV.D_E_L_E_T_ = ' '
INNER JOIN SA2010 AS SA2
ON A2_COD = RC1_FORNEC
AND RC1_LOJA = A2_LOJA
AND SA2.D_E_L_E_T_ = ' '
INNER JOIN SZM010 AS SZM
ON ZM_FILORIG = RE0_FILIAL
AND SZM.D_E_L_E_T_ = ' '
INNER JOIN SED010 AS SED
ON RC1_NATURE = ED_CODIGO
AND SED.D_E_L_E_T_ = ' '
WHERE RC1_FILTIT = '2B'
AND RC1_CODTIT = 'APT'
AND RC1_PREFIX = '2BP'
AND RC1_NUMTIT = '000009999'
AND RC1.D_E_L_E_T_ = ' ';
Esse Worktable nos mostra que essa query está utilizando muito tempdb:
Table 'Worktable'. Scan count 0, logical reads 655602 Table 'RC1480'. Scan count 1, logical reads 6 Table 'SA2010'. Scan count 1, logical reads 23442 Table 'RD0010'. Scan count 1, logical reads 1782
Olhando o plano de execução também podemos ver essa informação:
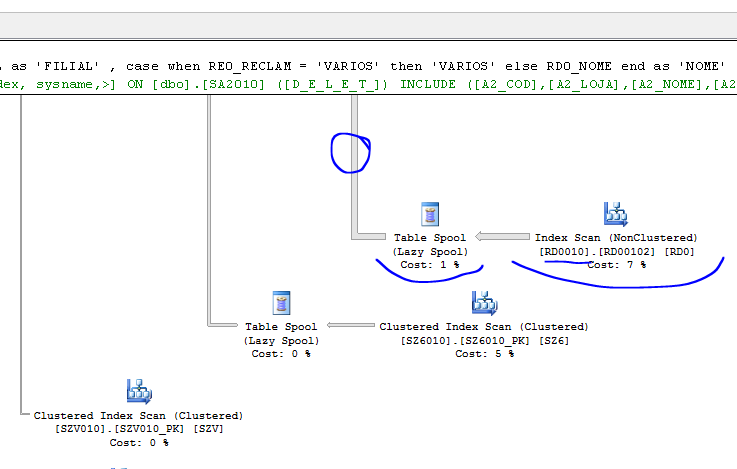
Quando virem um operador com “Spool” no nome, já visualizem que sua query está armazenando dados no tempdb para reutilizar esses dados posteriormente nesse plano.
Quando verem uma seta grande, significa que muito dado está sendo trafegado por ali.
Ou seja, pelo SET STATISTICS IO eu já tinha visto que o SQL estava usando o tempdb devido a quantidade de reads no Worktable. Eu abro o plano e vejo um Spool com uma seta desse tamanho.
Tenho que tentar ver algo nessa tabela RD0010 que está envolvida nessa bagunça toda.
Sem essa análise acima, nosso primeiro pensamento seria ir direto na tabela RC1480 que é utilizada pelo WHERE e criar um índice pela coluna abaixo:
AND RC1_NUMTIT = '000009999'
Contudo, não vou fazer isso. Vamos seguir na linha do tempdb primeiro.
Procurando a tabela RD0010 na query, vemos que um join é realizado com ela:
INNER JOIN RD0010 AS RD0 ON RD0_CODIGO = RE0_RECLAM AND RD0.D_E_L_E_T_ = ' '
Não existe índice nessa coluna RD0_CODIGO. Se eu criar, será que vai ajudar?
Vamos tentar…
Criando o índice:
CREATE NONCLUSTERED INDEX RD0010W01 ON [dbo].RD0010 (RD0_CODIGO,D_E_L_E_T_) INCLUDE (RD0_NOME) with(DATA_COMPRESSION=PAGE,FILLFACTOR=90)
Rodando a query novamente…. WOW!!!!
Milagrosamente sumiu aquele número gigante de leituras no tempdb:
Table 'Worktable'. Scan count 0, logical reads 535 Table 'RD0010'. Scan count 1, logical reads 3 Table 'SA2010'. Scan count 1, logical reads 23442 Table 'RC1480'. Scan count 1, logical reads 6
Muito bom Fabrício, mas ainda tem uma tabela fazendo mais 23 mil reads ai, não consegue resolver ela também?
Está bem… Vamos aproveitar a viagem e ver ela também .
Seguindo a mesma ideia da tabela anterior, criamos o índice abaixo pensando no join com essa tabela SA2010:
CREATE NONCLUSTERED INDEX SA2010W01 ON [dbo].[SA2010] ([A2_COD],[A2_LOJA],[A2_CGC],[D_E_L_E_T_]) INCLUDE ([A2_NOME],[A2_BANCO],[A2_AGENCIA],[A2_NUMCON]) with(DATA_COMPRESSION=PAGE,FILLFACTOR=90)
Rodando a query novamente, agora baixamos para 3 leituras de páginas também na SA2:
Table 'SA2010'. Scan count 1, logical reads 3
Colocando um waitfor delay na execução da query conseguimos visualizar no log de queries demoradas:
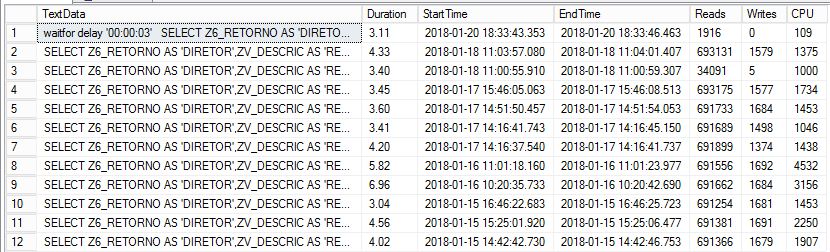
Ela rodou em 0,11 segundos e a diferença de leituras de páginas (691 mil para 2mil) e do consumo de CPU (2 mil para 100) é considerável!!!
É isso ai pessoal, melhoramos mais uma query no Protheus.
Com isso, encerramos essa série de Posts sobre Melhoria de Performance de Consultas Totvs.
A não Fabrício!!! Sério???
Sério…
Espero que tenha contribuído de alguma forma no seu aprendizado.
Atualizado no dia 07/10/2020:
Publiquei um curso com 11 horas de duração com toda minha experiência de anos no assunto e de dezenas de clientes Protheus atendidos:
Curso: Melhorando a Performance de Consultas no Totvs Protheus
Gravei uma aula grátis com 60 minutos de duração sobre o que você deve aprender para melhorar a performance no Protheus:
Gostou desse Post?
Curta, comente, compartilhe com os coleguinhas…
Assine meu canal no Youtube e curta minha Página no Facebook para receber Dicas de Leituras e Eventos sobre SQL Server.
Abraços,
Fabrício Lima
Microsoft Data Platform MVP
Consultor e Instrutor SQL Server
Trabalha com SQL Server desde 2006
Fabricio, Boa tarde tenho uma dúvida sobre esta questão de performance no Protheus e pelo que ví nesta sua série de posts é mito… Quanto acrescentamos os índices as tabelas do Protheus existe alguma regra que preciso seguir para não acarretar nenhum problema a execução do Protheus (erros internos por falta de informação em dicionario de dados, etc)? Ou somente preciso criar o índice e o Protheus deixará o Otimizador de consultar fazer a utilização do índice sem nenhum problema.
Aproveitando o ensejo parabéns pelos posts .. SENSACIONAL!!
Já vi poucos indices darem problema no protheus por alguma customização que fizeram… outras 99% das vezes, sem problema na criação dos índices.
Sobre regra:
Padronização seria bom abrir um chamado na totvs para confirmar, mas já nos pediram para manter um padrão com nome da tabela + W + 01..02..03 no indices
Sobre criar no dicionario, alguns clientes adicionam outros não.
Só aplico em tabelas que tem queries lentas… não em todas as tabelas da mesma empresa…
Obrigado pelo retorno Fabrício.
Só pra finalizar acredito que neste caso não seja mito, mais…. Segundo até mesmo em alguns fóruns que encontrei a aplicação de tempos em tempos apaga os objetos que não estão agregados ao dicionário de dados e por este motivo necessitaria criar uma verificação para ver se, de tempos em tempos, os itens que criamos precisariam ser recriado se for apagado.
Já teve este problema em ambientes que atendeu…
Sds,