
Melhorando a Performance de Consultas no Totvs Protheus – Parte 6

Fala pessoal,
Antes de lerem esse post, caso ainda não tenham lido os anteriores, sugiro que façam para seguirem a linha de raciocínio:
- https://www.fabriciolima.net/blog/2017/12/11/melhorando-a-performance-de-consultas-no-totvs-protheus-parte-1/
- https://www.fabriciolima.net/blog/2017/12/18/melhorando-a-performance-de-consultas-no-totvs-protheus-parte-2/
- https://www.fabriciolima.net/blog/2018/01/08/melhorando-a-performance-de-consultas-no-totvs-protheus-parte-3/
- https://www.fabriciolima.net/blog/2018/01/16/melhorando-a-performance-de-consultas-no-totvs-protheus-parte-4/
- https://www.fabriciolima.net/blog/2018/01/23/melhorando-a-performance-de-consultas-no-totvs-protheus-parte-5/
Hoje vamos analisar a query abaixo que está fazendo um número muito alto de leituras no banco:
SELECT RA_XREGIO XREGIO ,
RA_FILIAL FILIAL ,
RA_NOME NOME ,
RA_CIC CIC ,
RA_BCDEPSA BCDEPSA ,
RA_CTDEPSA CTDEPSA ,
ZT_TITULO TITULO ,
ZT_CODTIT CODTIT ,
ZT_MAT MAT ,
ROUND(ZT_VALVER, 2) VALVER ,
ZT_VERBA VERBA ,
ZT_XBCOFUN XBCOFUN ,
ZT_XAGEFUN XAGEFUN ,
ZT_XCTAFUN XCTAFUN ,
RC1_TIPO TIPO ,
RC1_EMISSA EMISSA ,
RC1_VENREA VENREA ,
RC1_VALOR VALOR ,
RC1_XBCO1 XBCO1 ,
RC1_XAGE1 XAGE1 ,
RC1_XCTA1 XCTA1 ,
RC1_XDTPAG XDTPAG ,
RC1_XUSPAG XUSPAG ,
RC1_XUSNPA XUSNPA ,
RC1.R_E_C_N_O_ RC1RECNO ,
RC1_NATURE NATUREZA
FROM SRA080 SRA ,
RC1080 RC1 ,
SZT010 SZT ,
SED010 SED
WHERE SRA.D_E_L_E_T_ = ' '
AND RC1.D_E_L_E_T_ = ' '
AND SZT.D_E_L_E_T_ = ' '
AND SED.D_E_L_E_T_ = ' '
AND RA_MAT = ZT_MAT
AND RA_SITFOLH IN ( ' ', 'A', 'D', 'F', 'T' )
AND ZT_CODTIT NOT IN ( ' ', '23', '234')
AND SUBSTRING(RA_BCDEPSA, 1, 3) IN ( '234', '543', '123', '987', '979' )
AND RA_FILIAL
BETWEEN '0 ' AND 'ZZ'
AND RA_MAT
BETWEEN '0 ' AND 'ZZZZZ '
AND RC1_NUMTIT
BETWEEN '0 ' AND 'ZZZZZZZZZ'
AND RA_XREGIO
BETWEEN '0 ' AND 'ZZ'
AND RC1_EMISSA
BETWEEN '20160101' AND '20171231'
AND RC1_VENREA
BETWEEN '20171212' AND '20171212'
AND RC1_NATURE IN ( '23243', '23423' )
AND RA_FILIAL = ZT_FILIAL
AND ZT_TITULO = RC1_NUMTIT
AND ZT_PREFIXO = RC1_PREFIX
AND ZT_CODTIT = RC1_CODTIT
AND ZT_RECTIT = RC1.R_E_C_N_O_
GROUP BY RA_XREGIO ,
RA_FILIAL ,
RA_NOME ,
RA_CIC ,
RA_BCDEPSA ,
RA_CTDEPSA ,
ZT_TITULO ,
ZT_PREFIXO ,
ZT_CODTIT ,
ZT_MAT ,
ZT_VALVER ,
ZT_VERBA ,
ZT_XBCOFUN ,
ZT_XAGEFUN ,
ZT_XCTAFUN ,
RC1_TIPO ,
RC1_EMISSA ,
RC1_VENREA ,
RC1_VALOR ,
RC1_XBCO1 ,
RC1_XAGE1 ,
RC1_XCTA1 ,
RC1_XDTPAG ,
RC1_XUSPAG ,
RC1_XUSNPA ,
RC1.R_E_C_N_O_ ,
RC1_NATURE
Segue o custo dessa query:
Table 'RC1080'. Scan count 1, logical reads 8832 Table 'SZT010'. Scan count 7961, logical reads 3017362 Table 'SRA080'. Scan count 9, logical reads 4710 Table 'SED010'. Scan count 3, logical reads 40 SQL Server Execution Times: CPU time = 5031 ms, elapsed time = 1074 ms.
3 milhões de reads na tabela SZT010. A treta da query está aí.
Esse é o plano da query:
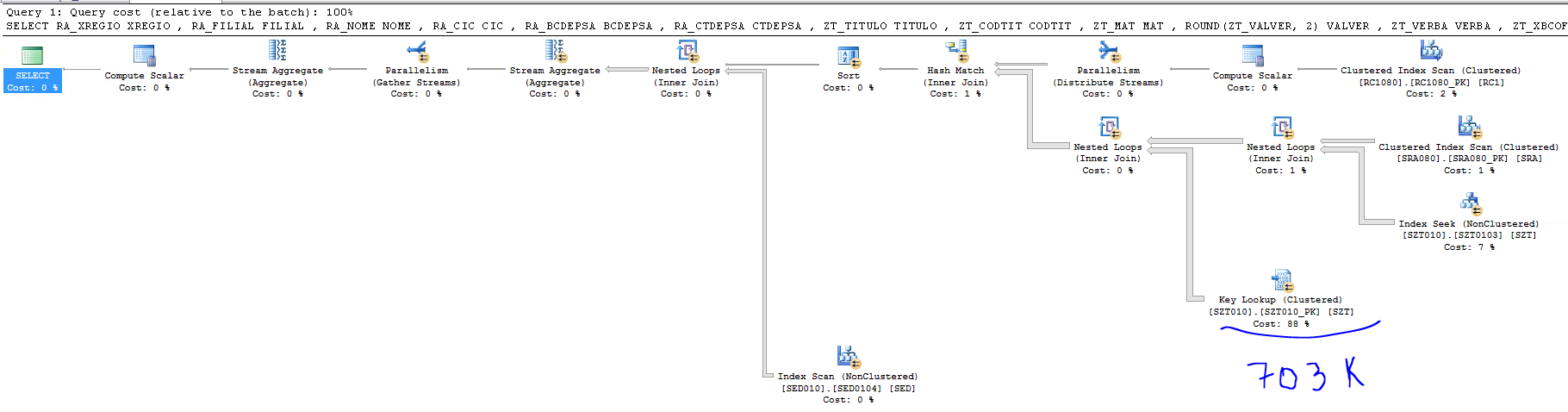
Como vimos que a treta está na tabela SZT, vamos procurar essa tabela no plano.
O SQL Server está realizando um Key Lookup 703 mil vezes no índice clustered dessa tabela.
Hummm… Olha aí o motivo da treta.
Mas Fabrício, agora o SQL Server não me sugeriu nenhum índice. Lascou. Só conseguia melhorar algo quando ele me mostrava.
Como não só de missed index vive o homem, vamos olhar para a query e pensar como ela poderia ser executada de forma mais rápida.
O Filtro mais seletivo que encontrei no WHERE foi esse abaixo:
AND RC1_VENREA BETWEEN '20171212' AND '20171212'
Dessa forma vou criar um índice na tabela RC1080 começando por essa coluna. Vou incluir nesse índice apenas as colunas utilizadas no WHERE para ele não ficar muito grande.
Em seguida, o SQL deverá fazer um join com a tabela SZT010 pelas colunas abaixo:
AND ZT_TITULO = RC1_NUMTIT
AND ZT_PREFIXO = RC1_PREFIX
AND ZT_CODTIT = RC1_CODTIT
AND ZT_RECTIT = RC1.R_E_C_N_O_
Para induzir o SQL a fazer isso, vou criar um índice que começa por essas colunas do join (a mais seletiva para a esquerda).
Segue abaixo os dois índices que criei:
CREATE NONCLUSTERED INDEX RC1080W01 ON [dbo].RC1080(RC1_VENREA,RC1_EMISSA,RC1_NATURE,RC1_NUMTIT) with (DATA_COMPRESSION=PAGE,FILLFACTOR=90) CREATE NONCLUSTERED INDEX SZT010W01 ON [dbo].SZT010(ZT_TITULO,ZT_PREFIXO,ZT_CODTIT,ZT_RECTIT,ZT_FILIAL,ZT_MAT,D_E_L_E_T_) include(ZT_VALVER, ZT_VERBA ,ZT_XBCOFUN ,ZT_XAGEFUN ,ZT_XCTAFUN) with (DATA_COMPRESSION=PAGE,FILLFACTOR=90)
Ao rodar a query novamente, temos mais um WOW!!!!
A quantidade de leituras reduziu drasticamente.
Consumo antes:
Table 'RC1080'. Scan count 1, logical reads 8832 Table 'SZT010'. Scan count 7961, logical reads 3017364 SQL Server Execution Times: CPU time = 5031 ms, elapsed time = 1074 ms.
Consumo depois:
Table 'SZT010'. Scan count 8, logical reads 32 Table 'RC1080'. Scan count 1, logical reads 27 SQL Server Execution Times: CPU time = 16 ms, elapsed time = 125 ms.
Redução de 3 milhões de leitura de páginas de 8 kb para 32 leituras e gerando o mesmo resultado. WOW!!!
Segue o novo plano da query:
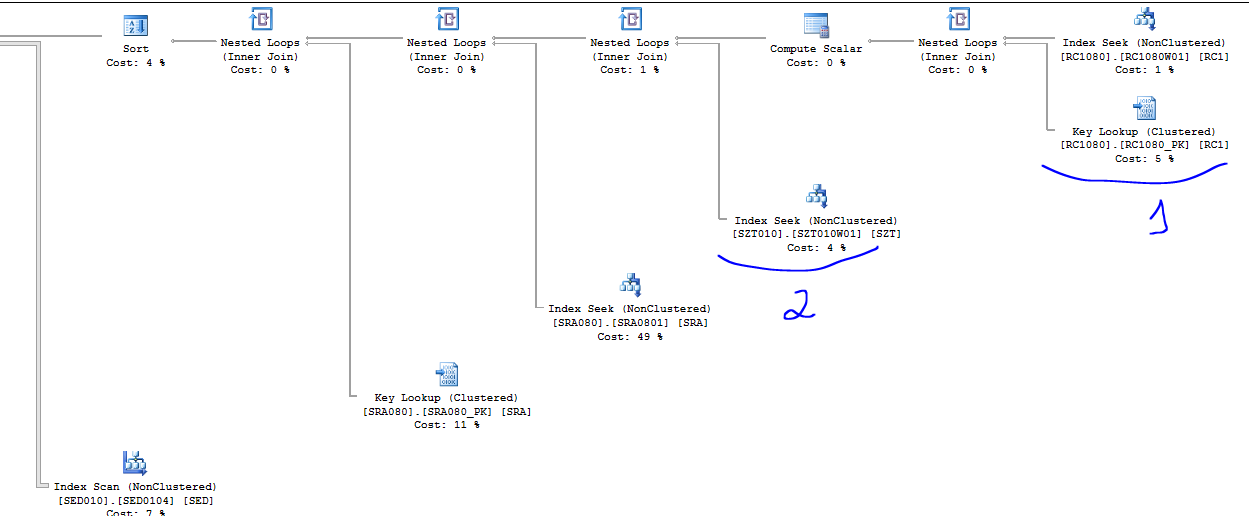
Com os dois índices que criei, eu induzi o SQL Server a rodar a query da forma que achei que seria mais rápida.
Ele já estava doido para rodar essa query dessa forma, só estava esperando um DBA/DEV criar esses índices para ele evitar de fazer 3 milhões de leituras e descansar um pouco.
É isso ai pessoal, melhoramos mais uma query no Protheus.
Até a próxima análise de query.
Atualizado no dia 07/10/2020:
Publiquei um curso com 11 horas de duração com toda minha experiência de anos no assunto e de dezenas de clientes Protheus atendidos:
Curso: Melhorando a Performance de Consultas no Totvs Protheus
Gravei uma aula grátis com 60 minutos de duração sobre o que você deve aprender para melhorar a performance no Protheus:
Gostou desse Post?
Curta, comente, compartilhe com os coleguinhas…
Assine meu canal no Youtube e curta minha Página no Facebook para receber Dicas de Leituras e Eventos sobre SQL Server.
Abraços,
Fabrício Lima
Microsoft Data Platform MVP
Fabricio, mas nesse caso a grande sacada é você ter feito o JOIN, certo? Os indices são o segundo passo… To certo?
Olá Danilo,
Nesse caso, a sacada foi identificar o filtro mais seletivo, a tabela (SZT010) com o maior número de Reads e as colunas dessa tabela que serão utilizadas no JOIN. Depois disso, criamos os índices e o SQL Server utilizou um plano de execução bem melhor. Portanto, antes do JOIN teria o filtro mais seletivo que é por onde o SQL Server irá começar o plano de execução. A criação dos índices é o último passo.
Abraço.